场景 ¶
这里我们把讨论限制在如下的使用场景中:
- 假设 1: 一个复杂的代码仓库有一个唯一的核心主线分支.
- 假设 2: 有多个开发者试图进行 non-trivial 的改动.
- 假设 3: 项目对代码质量有要求: 每个要合并的改动都必须经过充分 review 和测试.
- 假设 4: 适用对象不是开源项目里的路人随手 PR, 也不是实验性质的 prototype, 而是较为确定性的严肃的团队合作.
由于假设 2, 一个新 feature 往往要对仓库里的多个部分进行相对独立的改动, 例如在实现 feature X 的过程中, 我们可能会:
- 为模块 A 添加一个 API 及测试
- 顺便发现了模块 B 的一个 bug, 修复它并添加测试
- 对模块 C 的一个 API 进行了不兼容的改动并修改了它所有的 callsite
- 实现 feature X 及添加测试
- 完善关于 feature X 的文档和 release note
等等多个相对独立的步骤.
由于假设 4, 开发者知道自己的方向是大概率正确, (做少量修改后) 会被 reviewer 通过的. 因此为了提高效率, 在实现了部分改动 (例如 1-3) 后, 后续 (例如 4-5) 的开发不应被 code review block 住. 代码管理系统应当很好的支持这种 无阻塞的开发模式, 才能最大化团队的效率. 然而我们将发现, git + github 的设计并不鼓励这种开发模式.
Code Review 的基本单元: branch vs. commit¶
传统的基于 github/gitlab 的 workflow 具有这样的特性:
- Code review 的基本单元是 PR (在 gitlab 上叫 MR). 这是由 github 平台的 UI 设定的: 它的设计极大程度上鼓励用户对 PR 整体进行 review, 而不是去 review PR 里独立的 commit.(PR 里的每个 commit 虽然可以分开看, 但是体验上难以分开 review. 这里 有关于这一点的讨论.)
- Code review 的基本单元也是 branch, 因为 PR 与 branch 一一对应. 换句话说, 每个未被合并的 PR 必须存在于一个 branch 上, 且每个这样的 branch 上只能有一个未被合并的 PR.
而 stacked diffs workflow 的最重要的特性是: code review 的基本单元对应仓库里的 commits. 在 phabricator (Meta 使用的 code review 系统, 也被用于 llvm 等开源项目) 中这个单元叫做 "diff", 概念上对应 "PR".
Code review 的基本单元是 branch 还是 commit, 究竟有什么区别?
读者可能会认为, 在 github 上 review PR 的时候, 也是在 review commit. 但是, PR 里提供给 reviewer 的内容, 其实是通过 branch 的状态计算得来的: 每个 PR 有一个 target branch (例如下图中的pytorch:main) 和一个 featurebranch (例如ppwwyyxx:logging). Code review 的内容是它们之间的差别. 也就是说, 如果 feature branch 的内容发生变化 (例如有了新的 commit), PR 就会发生变化.

而在基于 commit 的 workflow 中, 甚至根本不需要 branch 这个概念: 我所有的工作都会是本地的一系列 commits, 它们被同步到 code review 系统里成为 diffs. 由于 diff 与单个 commit 对应, 添加新的 commit 并不会影响 code review 系统里现存的内容, 而会创建新的 diff. 如果要修改某个 diff 的内容, 我们可以把修改 amend 进这个 diff 对应的 commit.
说了这些基础概念, 接下来我们解释为什么 git + github PR 的 workflow 并不好用. 整个逻辑总结下来是这样的:
- git+github 的 workflow 里, "code review 单元 == PR == branch" (这一节)
- 复杂的开发应尽可能拆成多个独立的 code review 单元 (也即 PR) (下一节)
- Code review 不应阻塞开发: 我们需要能够在较早的 PR 还没完成 review (甚至没完成开发) 时, 就能够在其基础上开发后续的一系列 PR (上一节). 这些 PR 间自然就有了依赖关系
- 当较早的 PR 发生改动时, 我们需要对依赖它的后续 PR 做操作, 以维护 PR 间的依赖关系. 而 git + github 难以维护 branch 或 PR 间的依赖关系. (下下节)
Code Review 单元应尽可能拆小 ¶
这一节介绍一个普遍的工程实践: code review 单元应尽可能的小. 一个复杂的开发任务 应尽可能拆成不同的 code review 单元 而不是合在一起 review. 这是因为:
Code review 所需要的精力与 PR 长度并不成比例: 大的 PR 要比等量的小 PR 更难 review.
难以 review 带来的结果是, 大的 PR review 时间更长, 收到的 review 质量更低. 以上两点都是有很多研究佐证的, 例如 "Modern Code Review: A Case Study at Google" 这篇 paper.
Review 是有延迟的. 分开独立的 code review 使得 较早的改动在被 accept 后可以尽早合并, 这样能 (i) 减少冲突; (ii) 尽早被别人使用, 触发可能的问题.
举例来说, 假如一个工作的第一部分可以很快被 accept, 而其他部分还需要讨论 & review 一周. 如果我们等整体被 accept 了再全部一起合并, 则第一部分可能会与这一周里其他改动产生合并冲突, 而这种冲突本可以完全避免.
尽早将已完成的小部分工作拿出来 review, 这样被 reviewer 发现问题可以及时调整后续路线. 否则的话, 如果憋了个大招一起 review, 再发现问题调整起来就会额外花很多工作量.
不同模块的改动可能需要由不同的人来 review. 合在一起 review 会给每个 reviewer 增加额外的心智负担: review 时要找 "哪些是我该看的?". 不断收到 code review 平台发送的新的通知要想 "跟我有没有关系?"
合并进仓库的 commit 历史应该与 code review 单元一一对应 (而不应多对一). 当回看 commit 历史时, 小的, 一次只解决一个独立问题的 commit 会看起来更清晰, 找问题也会更容易.
因为这些原因, 好的工程实践是 鼓励将大的单个改动拆成多个小的部分, 分开进行 review 和提交. 每个部分各自需要逻辑上是一个完整的, 正确的小单元. 一个改动通常不超过 100 行, 原则上不超过 300 行.
Google 的 "Modern Code Review" 论文中也说:
Developers are strongly encouraged to make small, incremental changes.
Software Engineering at Google 这本书中有一节叫做 "Write Small Changes". 好处上面已经分析过了就不再重复, 这里摘录一些其中的数据:
“Small” changes should generally be limited to about 200 lines of code. ... Most changes at Google are expected to be reviewed within about a day.
... About 35% of the changes at Google are to a single file.
Software Enginering at Google 一书写成时, Google 内部的 stacked diff 工具还不成熟, 因此实操的便捷性被书中列为一个缺点. 本篇文章正要介绍如何用更好的工具解决这个问题. 除此之外, 有时后, 拆分会导致各部分的总和略大于单个改动; 有时, 为了将一个大规模改动 (例如重构) 变得 "可以拆分", 甚至需要额外做一些工作 (例如增加兼容层). 但 "small incremental change" 的优点值得这些额外的付出.
如何管理 code review 间的依赖关系 ¶
当有多个互相依赖的小的 code review 后, 需要工具来自动化的管理它们的依赖关系. 笔者在 Meta 和 Google 都使用本地的 mercurial 仓库配合 Meta/Google 内部的 code review 工具. 这套 workflow 可以非常方便的管理 code review 间的依赖.
下面以几个例子说明 Meta 的基于 mercurial 仓库 + Phabricator Diff 的 workflow 为什么优于 git 仓库 + github PR 的 workflow. 在每个例子中, 用😞来表示体验糟糕的部分.
Example 1: 我们以这样两个改动开始:
- 改动 A: 为模块 A 添加一个 API 及测试
- 改动 X: 基于 A 来实现 feature X 及添加测试
它们有依赖关系 A <- X . 在 Meta, 我会这么做:
- 两个改动就是本地仓库 main branch 的两个 commit. 不管我当前的 checkout 是哪个 commit, 从
hg log里都能看到全部两个. - 通过一个命令可以将两个 commits 一起发送到 phabricator 上成为两个 diff.
- 它们可以被独立 review, UI 会显示它们的依赖关系.
如果使用 github, 我将不得不这么做:
- 😞取两个新 branch 的名字 (这里暂且叫 branchA 与 branchX).
- 在 branchA 实现改动 A 后, 在另一个 branchX 实现改动 X. 😞只有 branchX 的
git log能看到两个改动, branchA 只能看到改动 A. - 😞用 至少两个命令 将两个 branch 分别 push. 一个命令做不到, 因为 git 仓库并不知道 branch 之间有依赖关系.
- 从这两个 branch 创建两个 PR. 注意这里 PR A 的 merge target 是项目的 main branch, 而 PR X 的 merge target 需要是 branchA (否则这个 PR 里就会有两个改动, 没法独立 review 了). 😞merge target 需要一些手工操作来设置, 因为 github 并不知道两个 branch 的依赖关系.
- 😞PR X 的 UI 上能看到 merge target 是 branchA, 但是看不到 PR A 的链接. 要方便的链接到 PR A 还得用其它工具 (或手动描述). 这主要是个 UI 问题.
Example 2: 继续上一个 example, 在经过一些 review 后, 我们需要对改动 A 的内容进行修改. 在 Meta 我会这么做:

- 本地 amend commitA. 默认自动触发 rebase commitX. 这样本地仍然是两个 commits. 通过一个命令将 phabricator 上的两个 diff 都同步到最新.
- phabricator 会保存旧版本的 commitA, 如果要看旧版本也有办法.
- reviewer 可以选择 review 完整的 commitA, 也可以选择 review commitA 的增量.
如果使用 github, 我需要:
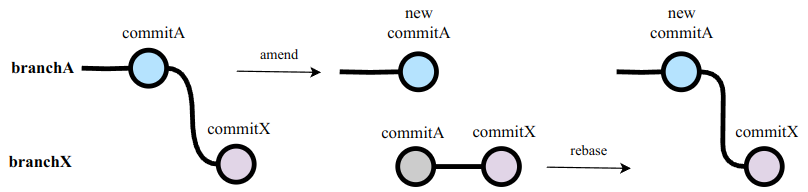
- 在 branchA 上加入额外的 commitA-fix 再 push. 或者在 branchA 上 amend commitA 再 force push. 😞它们各有各的问题:
- amend 没法很好的保留旧的 commitA (这单纯是个 github UI 的问题, 而不是 git 的问题).
- amend 会导致 rebase branchX on branchA 的时候产生 conflict. (下一节解释)
- 如果在 branchA 里加入一个不干净的 commitA-fix (即并不需要最终保留在 main branch 里的 commit), 在 rebase branchA on main 时会带来很多不必要的痛苦. 例如: 假设 commitA 和 commitA-fix 都对函数 func 进行了修改. 而与此同时 main branch 的 func 也有了变化. 这时候 rebase branchA on main 时需要 resolve conflict 两次.
- 😞无论怎样, 都需要再手动切换到 branchX, rebase on branchA, 再 force push branchX, 才能维护好它们的依赖关系.
Example 3: 接着上一个 example, 在经过一些 review 后, 我们发现需要额外对函数 S 进行修改才能更好的实现 feature A. 也即依赖关系为S <- A <- X. 在 Meta 我会这么做:

- 直接在 base 的基础上添加 commitS.
- 一个命令将 commitA 和 commitX rebase 到 commitS 上. 如有需要, amend commitA 和 commitX 的内容
- 一个命令将 phabricator 的状态与本地同步, 即: 创建新的 diffS, 更新已有的 diffA, diffX, 并更新三个 diff 间的依赖关系.
如果使用 github, 我需要:
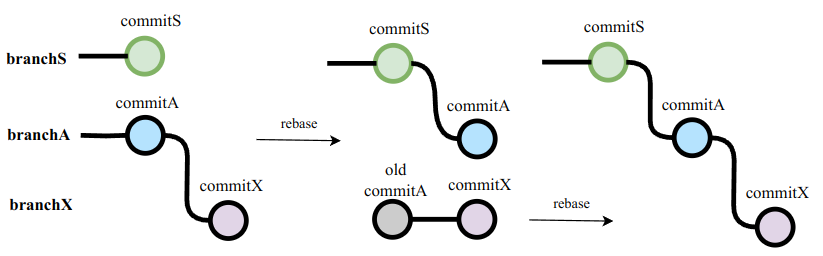
- 从 main branch 开辟新 branchS, 添加 commitS
- rebase branchA on branchS, 如有需要, 修改 branchA 的内容.
- 😞再次 rebase branchX on branchA.
- 😞类似 Example1 中的缺点, 我们这里需要分别 push branchS, branchA 和 branchX, 并且手动将 PR A 的 merge target 改为 branchS.
- 😞UI 问题: 在 PR X 里能看到它对 branchA 的依赖, 但看不到它对 branchS / PR S 的依赖.
Example 4: 接着上一个 example, 假如我们有S <- A <- X <- Y 的依赖链, 此时 S 和 A 都被 accept, 我们想要尽快将其合并, 并在合并后的最新主线上继续开发 X 和 Y. 在 Meta 我会:
- 在 phabricator 上用按钮将其合并.
- 在本地仓库里 rebase on main. rebase 完成后本地只剩下 commitX 和 commitY. 一个命令同步这两个 diff 的状态.
而使用 github 时, 我需要:
- 在 github 上操作将 S 合并
- 😞在 github 上再次操作, 将 PR A 的 merge target 设为 main branch, 再将 A 合并
- 本地将 branchX rebase on main. 😞将 branchX push 到 PR X 并手动把 merge target 设为 main branch.
- 😞再将 branchY rebase on branchX. push branchY.
从这几个例子可以看出, github workflow 的本质缺点在于: 无论是 git 还是 github 都 没有充分的关于 branch 之间的依赖关系 (也即 PR 之间依赖关系) 的信息. 这带来的主要问题是:
当多个 PR 的依赖链条较长时, 每次改变中间 PR 的内容, 或合并 / 删除了某个中间 PR 后, 都需要一个个手动 rebase 所有依赖它的后续 branch, 并手动 push github. 有时候还需要手动改 github merge target.
而当 commit 作为工作单元时, 以上这些工作都可以自动完成: 当中间 commit 被改动时, 所有需要被 rebase/push 的 commit 都可以通过依赖关系自动找到.
Commit Identifier¶
除了依赖关系的缺失之外, 另一个 git/github 的缺点是, branch 之间 rebase 有更大的概率产生 conflict. 这是由于缺少一种 commit identifier 机制.
什么是 commit identifier? 在基于 branch 的 workflow 里, 本地 branch 与远端 PR 通过 "branch 的名字" 这个 identifier 来匹配. 在基于 commit 的 workflow 里, commit 与远端 diff 也需要一种匹配机制, 工具才知道每个 commit 应该更新哪个 diff. 它的实现方式一般通过本地工具 (如 hg) 在 commit metadata 里添加一个随机 unique identifier 来实现. 同时, 本地工具需要维护这个 identifier, 确保一个 commit 在经历了 rebase, reorder, amend 等操作后 identifier 不变, 且在 squash 操作时询问用户保留哪个 identifier. 这个 commit identifier 替代了 "branch 名字" 的功能.
不仅如此, commit identifier 能使得 rebase 的体验更加的丝滑. 例如, 在上一节的 Example 2 中, 我们要将 branchX rebase 到修改后的 branchA 上:
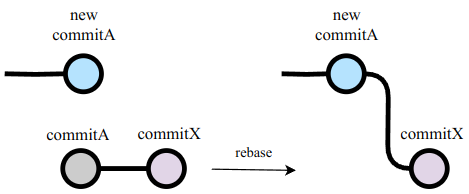
图中的 rebase 并没有想象中那么简单: 由于 git 并不知道 commitA 与 new commitA 之间有任何关系, git 会尝试将 commitA, commitX 分别应用到 new commitA 上. 而将 commitA 应用到 new commitA 上几乎一定会产生 conflict. 然而, 当有了 commit identifier 后, rebase 工具通过 identifier 和 commit 时间知道 "new commitA" 是最新版的 "commitA", 就可以直接避免这个 conflict.
另外, 一个常见的小问题是 github PR 的 inline comment 经常会在 force-push 之后丢失, 这同样是因为 github 不知道新的 commit 与旧的的对应关系.
From Stack to DAG¶
不难想到, 不同的 PR/diff 之间的依赖关系未必是一条单链表, 而可以是一个有向无环图 (DAG). 这种依赖关系就更难在 git 中处理了, 这是 git 的另一个小缺点.
相较于 git branch 内的所有 commits 必须是一条直线, 一个 mercurial 仓库的本地 workspace 可以包含分支, 例如, 我可以在本地创建这样 5 个 WIP 的 commits, 它们可以有 DAG 的依赖关系:
|
由于 code review 与 commits 对应, 这 5 个 commits 将成为 5 个 "diff" 以供 review. Phabricator 的 UI 上也可以显示 diff 间的 DAG 关系, 例如:
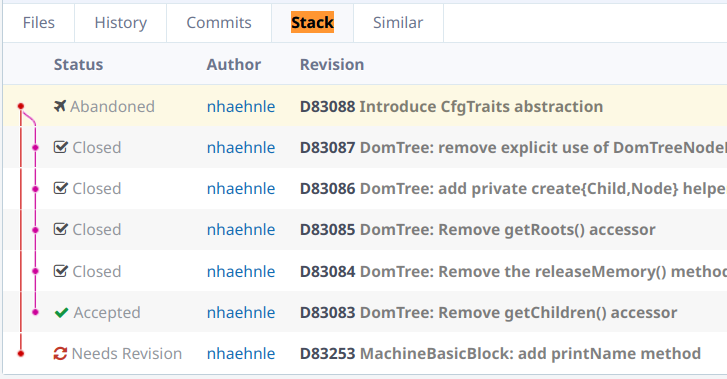
让 git + github 更好 ¶
在 Meta/Google 工作时, 我的 mercurial workspace 里通常有数十个开发中的 commits, 对应着 code review 平台上的 diffs (在 Google 又叫 CL). 它们可能有复杂的 DAG 依赖, 也可能是独立的. 它们有的是严肃的开发, 有的是 prototype, 有的只用来临时 debug, 但是没关系, 因为我可以选择哪些 commits 要给人 review, 不会受到新增 commits 的影响. 我也可以方便的通过 amend/rebase 修改 commits 或它们的依赖关系, 并且所有修改都可以一键与 code review 平台同步. 在 git 上如何复刻这种体验, 仍然是个难题.
如果要在不改变 git / github 的情况下, 实现接近 stacked diff 的 workflow, 就需要实现一个新的 git 仓库管理工具, 负责:
- 为每个 commit 创建 branch, 并记录他们的依赖关系
- 通过依赖关系, 进行自动的 rebase 等维护工作
- 为每个 commit 创建一个 identifier, 据此维护 commit 与 PR 的对应关系
- 在本地显示 commits 之间 DAG 形态的依赖, 用于替代
git log. - 将必要的依赖信息通过 github API 更新到 PR 上
有一些工具已经部分实现了这些功能, 例如:
- ghstack: PyTorch 团队开发的的 stacked PR 工具. 除了 readme 提到的一些小问题外体验还不错.
- git-spr: 试过一次, 当时体验并不好.
- git-branchless: 有 DAG 及自动 rebase 等的功能. 本地体验还不错, 但并没有和 github 整合.
- jj: 有 DAG 及自动 rebase 等功能, 但并没有和 github 整合. 作者是 google 内部 stacked diff 工具 (fig) 团队成员. 试了一下, 操作和传统 git 的差距有点大, 不太习惯.
- git-patchstack: 没用过.
- graphite: 一个专注做 stacked PR 工具的 startup. 没用过但是看上去做的很认真.
- aviator: 也是一个专注做 stacked PR 工具的 startup.
最后, 关于 stacked diffs 的话题, 这里提供一些其他参考:
上面两篇文章写的最详细, 本文也参考了其中的一些观点. 除此之外, 还有:
- Stacked diffs and ghstack: ghstack 作者的 podcast.
- git-patchstack 开发者的文章: How we should be using Git, 和它们的文档
- graphite 开发者的文章: Stacking
- aviator 开发者的文章: Rethinking code reviews with stacked PRs
- In-Praise-of-Stacked-PRs
- Taichi 开发团队也使用 ghstack, 在 B 站有个中文教程
注: 本文大部分写于离开 Meta 的 Stacked Diff 后, 在 Cruise 工作期间. 当时苦于 Cruise 用 github 没有 Stacked Diff. 然而文章还没写完我就去了 Google, 又有了 Stacked Diff. 如今再次回到 git 的世界, 所以又开始研究这个问题.
]]>