Not Every Model Has a Separate "Loss Function"
"Loss function" is one of the most basic concepts today in deep learning. Despite that, it is actually not necessarily a good programming abstraction when designing general-purpose systems. A system should not assume that a model always comes together with a separate "loss function".
"Loss Function": Separation of Logic¶
"Loss function" may mean different things in different systems. The version I'm going to criticize is the most common one that looks like below:
| Bad | Worse | ||
|---|---|---|---|
|
|
The key property of a bad "loss function" abstraction is: Users are asked to provide a "loss function" that's executed separately after the "model / forward logic". Such abstraction appears in a few open source systems: Keras model.compile(loss=), fast.ai Learner(loss_func=), Lingvo BaseModel.ComputeLoss.
The main problem is not with the function itself, but that the users' algorithm logic is forced to separate into two parts: model and loss_func.
As an alternative, trainer_good below no longer separates "loss_func" from the model, and has equal functionalities
with trainer_bad.
|
In this article, I want to argue that this is a better design because:
- Separating out "loss function" causes many trouble.
- With
trainer_good, users can still separate theirmodelinto two parts if they like, but they don't have to. - Although
trainer_goodis no longer aware of the separation, it does not matter.
(Apparently, trainer_good == partial(trainer_bad, loss_func=lambda x, y: x).
So trainer_bad can still be used - we just set loss_func to a no-op if we don't like it.
But trainer_good is cleaner.)
Problems of a Forced Separation¶
It's true that the separation can be useful to certain types of models. But it's not always the case, and enforcing it can be harmful instead.
Duplication between "Model" and "Loss"¶
The separation is not convenient for a model with many optional losses. Take a multi-task model for example:
| Separation | No Separation | ||
|---|---|---|---|
|
|
The right one is simpler in that it does not duplicate the
branches that enable different tasks/losses.
In reality, these conditions are often more complex than a simple if,
and branching is generally less straightforward to maintain.
So it's beneficial to not have to repeat the logic.
Note: If you think a wrapper like
multi_loss_func({"task1": loss_func1, "task2": loss_func2})
will help (like what Keras supports), it is not going to work well
because it doesn't know how to route the inputs/outputs to loss functions.
"Loss" is not Independent of "Model"¶
One may argue that separating "loss" from "model" is nice because then we can easily switch different loss functions independent of "model". That is indeed useful in many cases. However, in many algorithms, loss computation is simply not independent of the model and should not be switched arbitrarily. This could be due to:
-
Loss computation depends on internal states computed during
model.forward, e.g.:- Loss needs to know which part of training data is sampled during
forward. - Some predicted auxiliary attributes control whether a sample in a batch should participate in losses.
- Losses such as activation regularization should naturally happen during
forward.
In these cases, forcing a separation of "loss" and "model" will require "model" to return its internal states, causing an abstraction leak.
- Loss needs to know which part of training data is sampled during
-
Different loss functions expect different representations of model's predictions. For example, these representations could be:
- Discrete vs. one-hot encoding of class labels.
- Boxes represented as absolute coordinates, or as reference anchors plus offsets.
- Segmentation masks represented as polygons, binary bitmasks, or many other formats.
Since conversion between representations may be expensive or lossy, we'd like the model to produce the exact representation needed by loss computation. Therefore, a separation would not make model independent of losses. On the contrary, it's even worse because loss-related logic will be unnaturally split like this:
| Separation | No Separation | ||
|---|---|---|---|
|
|
We can see in the above snippet that the model is in fact
not independent of losses.
It also makes loss_func a bad abstraction because the semantics
of its prediction argument is complex: it should be
in different formats depending on which of loss{1,2} is used.
In the version with no separation, it's very clear
that the losses are computed using the right representation.
No Clean Separation¶
One may argue that the separation is helpful because it's nice to let the "model" return the same data in training and inference. This makes sense for simple models where training and inference share most of the logic. For example, in a standard classification model shown below, we can let the "model" object return logits, which will be useful in both training and inference.
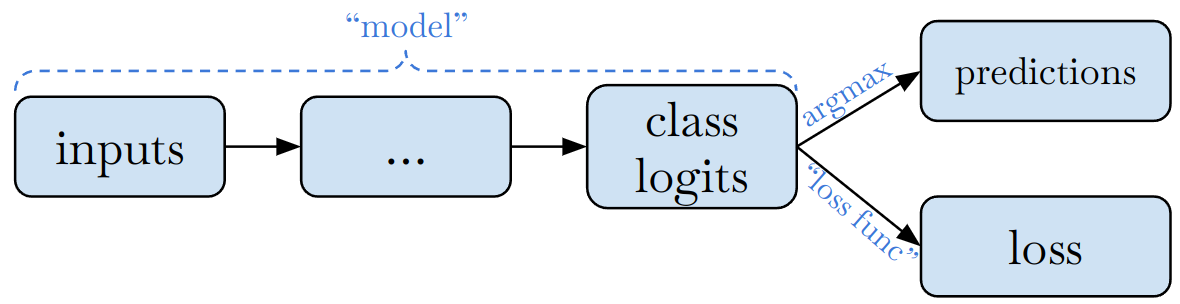
But many models don't have a clean separation like this. In theory, training and inference only have to share (some) trained weights, but don't necessarily have to share any logic. Many object detection models, for example, do not compute "predictions" in training and do not compute losses in inference. A simplified diagram of Region-Proposal Network (RPN) of a two-stage detector looks like this during training:
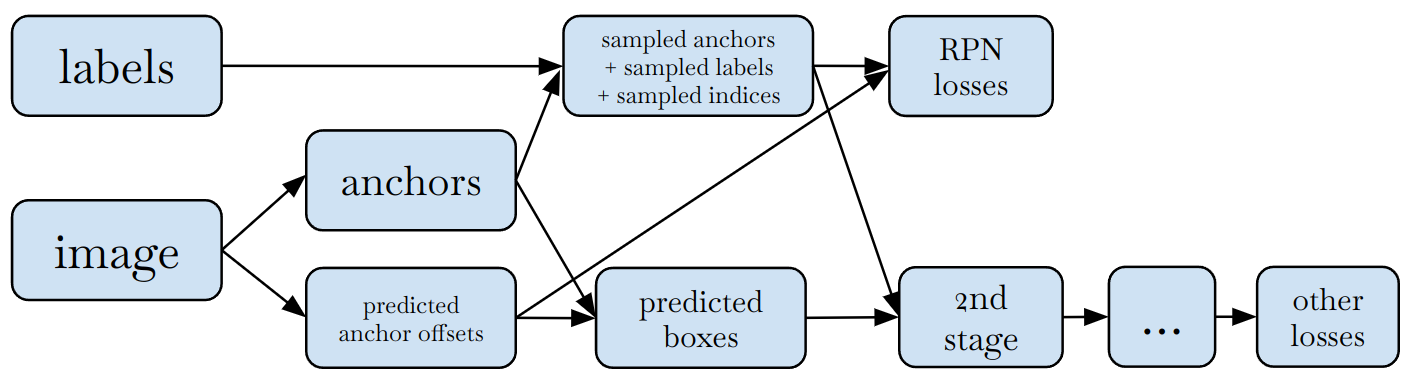
Any attempt to split a complicated algorithm like this into "model" and "loss function" will:
- Force "model" to return its internal algorithmic details that are not useful anywhere, except in a corresponding "loss function". This is an abstraction leak.
- Make code harder to read, because closely related logic is separated in an unnatural way.
- Lead to higher memory usage (if executing eagerly), because some internal states have to be kept alive until "loss function" is called after the "model".
Therefore, it's unrealistic to expect that there is a nice separation, or that "model" can produce
a consistent format in both training and inference.
A better design is to include loss computation in the model's training-mode forward, i.e., let model output
losses in training, but predictions in inference.
Trainer Does Not Need to Know about the Separation¶
| Separation | No Separation | ||
|---|---|---|---|
|
|
In the "no separation" design, users provide a "model" that returns losses. This model internally can still use separation of "loss function" and "forward logic" as long as it makes sense for this specific model. However, trainer is no longer aware of the separation, and the trainer can no longer obtain the "outputs".
Will this become a limitation of the "no separation" design? What if we'd like to do something with "outputs"? My answer is:
- For 99% of the use cases where the "outputs" don't directly affect the training loop structure,
trainer doesn't need to know about "outputs".
- For use cases where the trainer does something non-critical (not affecting loop structure) with "outputs", a proper design would move such responsibility away from trainer.
- For example, writing "outputs" to tensorboard shouldn't be a responsibility of trainer. A common
approach is to use a context-based system
that allows users to simply call
write_summary(outputs)inside their model.
- For other obscure use cases, they should have custom trainers anyway.
Summary¶
Design is always a trade-off. Adding assumptions to a system might result in some benefits, but at the same time can cause trouble when the assumption isn't true. Finding a balance in between is difficult and often subjective.
The assumption that models have to come together with a separate "loss function", in my opinion, brings more trouble than it's worth.